RNA Protein Integration#
[ ]:
%%bash
git clone https://github.com/Zafar-Lab/multiHIVE.git
pip install scvi-tools
pip install scanpy
pip install anndata
pip install scikit-misc
[1]:
import scvi
import scanpy as sc
from multiHIVE import multiHIVE
/home/anirudhn/anaconda3/envs/test3111/lib/python3.11/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
/home/anirudhn/anaconda3/envs/test3111/lib/python3.11/site-packages/docrep/decorators.py:43: SyntaxWarning: 'param_categorical_covariate_keys' is not a valid key!
doc = func(self, args[0].__doc__, *args[1:], **kwargs)
/home/anirudhn/anaconda3/envs/test3111/lib/python3.11/site-packages/docrep/decorators.py:43: SyntaxWarning: 'param_continuous_covariate_keys' is not a valid key!
doc = func(self, args[0].__doc__, *args[1:], **kwargs)
[2]:
adata = scvi.data.pbmcs_10x_cite_seq()
adata
INFO File data/pbmc_10k_protein_v3.h5ad already downloaded
INFO File data/pbmc_5k_protein_v3.h5ad already downloaded
/home/anirudhn/anaconda3/envs/test3111/lib/python3.11/site-packages/scvi/data/_built_in_data/_cite_seq.py:47: ImplicitModificationWarning: Setting element `.obsm['protein_expression']` of view, initializing view as actual.
dataset1.obsm["protein_expression"] = pd.DataFrame(
/home/anirudhn/anaconda3/envs/test3111/lib/python3.11/site-packages/scvi/data/_built_in_data/_cite_seq.py:52: ImplicitModificationWarning: Setting element `.obsm['protein_expression']` of view, initializing view as actual.
dataset2.obsm["protein_expression"] = pd.DataFrame(
/home/anirudhn/anaconda3/envs/test3111/lib/python3.11/site-packages/anndata/_core/anndata.py:1756: UserWarning: Observation names are not unique. To make them unique, call `.obs_names_make_unique`.
utils.warn_names_duplicates("obs")
[2]:
AnnData object with n_obs × n_vars = 10849 × 15792
obs: 'n_genes', 'percent_mito', 'n_counts', 'batch'
obsm: 'protein_expression'
[3]:
adata
[3]:
AnnData object with n_obs × n_vars = 10849 × 15792
obs: 'n_genes', 'percent_mito', 'n_counts', 'batch'
obsm: 'protein_expression'
[4]:
adata.obsm['protein_expression'].shape
[4]:
(10849, 14)
[5]:
adata.layers["counts"] = adata.X.copy()
sc.pp.normalize_total(adata)
sc.pp.log1p(adata)
adata.raw = adata
[8]:
sc.pp.highly_variable_genes(
adata,
n_top_genes=4000,
flavor="seurat_v3",
batch_key="batch",
subset=True,
layer="counts"
)
multiHIVE.setup_anndata(
adata,
layer="counts",
batch_key="batch",
protein_expression_obsm_key="protein_expression"
)
INFO Using column names from columns of adata.obsm['protein_expression']
/home/anirudhn/anaconda3/envs/test3111/lib/python3.11/site-packages/anndata/_core/anndata.py:1756: UserWarning: Observation names are not unique. To make them unique, call `.obs_names_make_unique`.
utils.warn_names_duplicates("obs")
/home/anirudhn/anaconda3/envs/test3111/lib/python3.11/site-packages/anndata/_core/anndata.py:1756: UserWarning: Observation names are not unique. To make them unique, call `.obs_names_make_unique`.
utils.warn_names_duplicates("obs")
/tmp/ipykernel_95030/1335140093.py:10: DeprecationWarning: multiHIVE is supposed to work with MuData. the use of anndata is deprecated and will be removed in scvi-tools 1.4. Please use setup_mudata
multiHIVE.setup_anndata(
[ ]:
import numpy as np
import matplotlib.pyplot as plt
vae = multiHIVE(adata,
n_genes=4000,
n_regions=0,
n_proteins=14
)
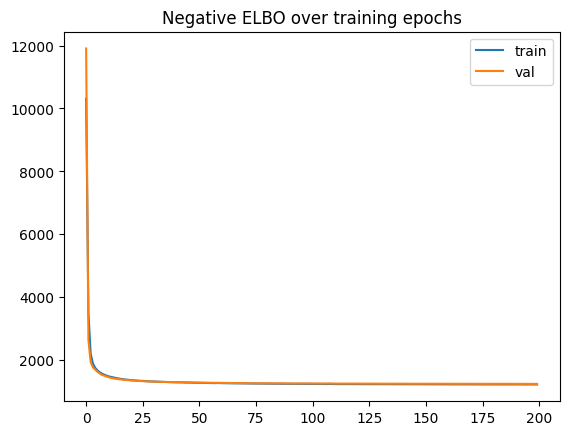
vae.train(max_epochs=200)
vae.get_latent_representation()
INFO Computing empirical prior initialization for protein background.
INFO:pytorch_lightning.utilities.rank_zero:GPU available: False, used: False
INFO:pytorch_lightning.utilities.rank_zero:TPU available: False, using: 0 TPU cores
INFO:pytorch_lightning.utilities.rank_zero:IPU available: False, using: 0 IPUs
INFO:pytorch_lightning.utilities.rank_zero:HPU available: False, using: 0 HPUs
/usr/local/lib/python3.11/dist-packages/pytorch_lightning/core/optimizer.py:331: RuntimeWarning: The lr scheduler dict contains the key(s) ['monitor'], but the keys will be ignored. You need to call `lr_scheduler.step()` manually in manual optimization.
rank_zero_warn(
Epoch 200/200: 100%|██████████| 200/200 [47:37<00:00, 14.22s/it, v_num=1]
INFO:pytorch_lightning.utilities.rank_zero:`Trainer.fit` stopped: `max_epochs=200` reached.
Epoch 200/200: 100%|██████████| 200/200 [47:37<00:00, 14.29s/it, v_num=1]
<matplotlib.legend.Legend at 0x7ee7202abcd0>
[12]:
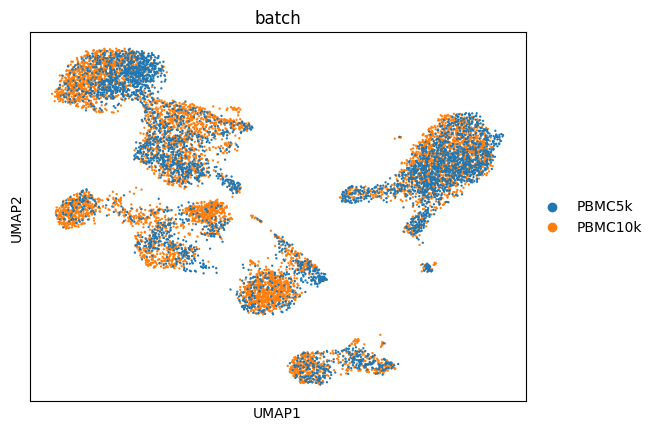
sc.pp.neighbors(adata, use_rep = "Z_multiHIVE")
sc.tl.umap(adata)
sc.pl.umap(adata, color = "batch")